
機器學習基石 (Machine Learning Foundations)---Mathematical Foundations学习笔记,温故而知新。笔记中会掺杂自我思考的内容,如有理解的谬误之处,有则改之无则加勉。
1.什么是机器学习
什么是机器学习(What)
对于要学习的一门学科,我们很自然的要提出一个问题,什么是机器学习?或者说机器学习的定义是什么?
对于这个问题,早期的学术泰斗们给出了严谨的定义:
A computer program is said to learn from experience E with respect to some class of tasks T and performance measure P, if its performance at tasks in T, as measured by P, improves with experience E.
相较于朴素而严格的定义,我们对机器学习可以有更通俗的解释:
机器学习过程就是利用数学模型从历史观测数据中寻找、捕捉潜在的模式或规律并对未知数据进行推理的过程
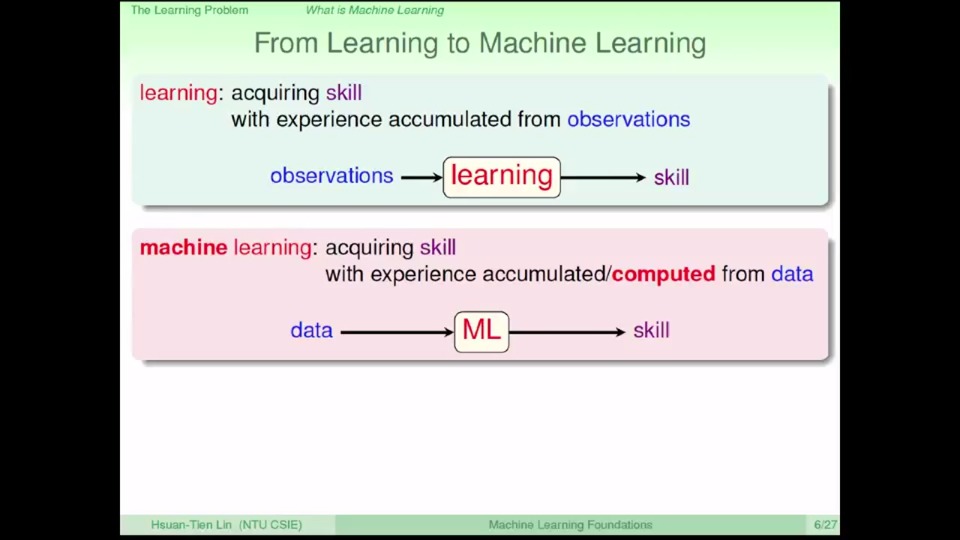
tips:机器学习是更广泛的"人工智能"领域下的一个分支,被认为是人类实现人工智能的一个重要路径之一。由于目前的机器学习学科大量运用了统计学的方法,因此机器学习也称为"统计机器学习"
当先入为主的被动了解了基本定义之后,我们要判断为什么要学习?和为什么要使用机器学习方法?
为什么使用机器学习(why)

机器学习方法是解决复杂问题的一条可选路径,可以间接解决已有方法无法解决的问题(如视频换脸技术),在一些领域可以比传统方法的效果更好(图像识别、CTR预估等)
tips: 我们背后是将机器学习方法和传统的方法进行比较。机器学习方法我习惯归类为"基于数据驱动的方法"而传统方法比较依赖业务场景或领域知识
,这类方法我称为"基于机理模型的方法"或"基于模型驱动的方法"。对于从业者而言,机器学习类方法侧重于评价效果而弱化可解释性,模型发生作用的机理不透明(需要一定的数理基础),类似"黑盒";而传统方法拥有扎实的领域理论支撑,机理透明且经过充分的实证检验。
什么时候可以尝试使用机器学习(when)
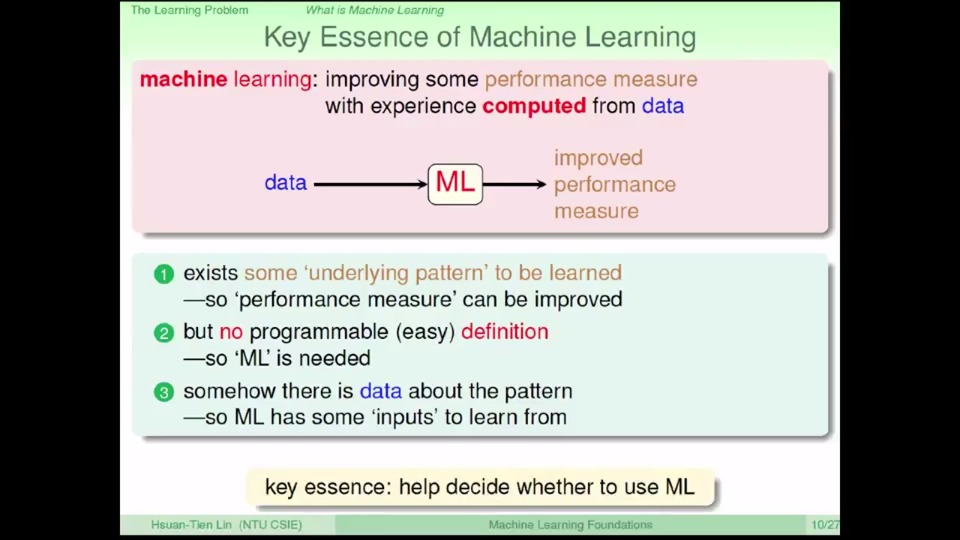
天下没有免费的午餐,使用机器学习方法需要满足一定基本条件。
- 要解决的问题可能遵循某种未知规律而非随机(如预测婴儿啼哭问题)
- 无法通过简单的特定规则定义的问题(如判断矩阵中是否存在圆)
- 需要帮助模型发现潜在模式的观测样本数据(预测地球何时毁灭?)
tips:如果我们定义的问题满足基本条件,只是说明我们"可以""尝试"使用机器学习方法来解决,并不代表一定会用机器学习模型去解决。
如果不是纯粹的研究用途或者刷比赛,问题和解决方案一定是收到收益/成本(ROI)的制约。需要在好商业目标和方法探索、部署成本中寻找平衡点。
2.机器学习相关应用
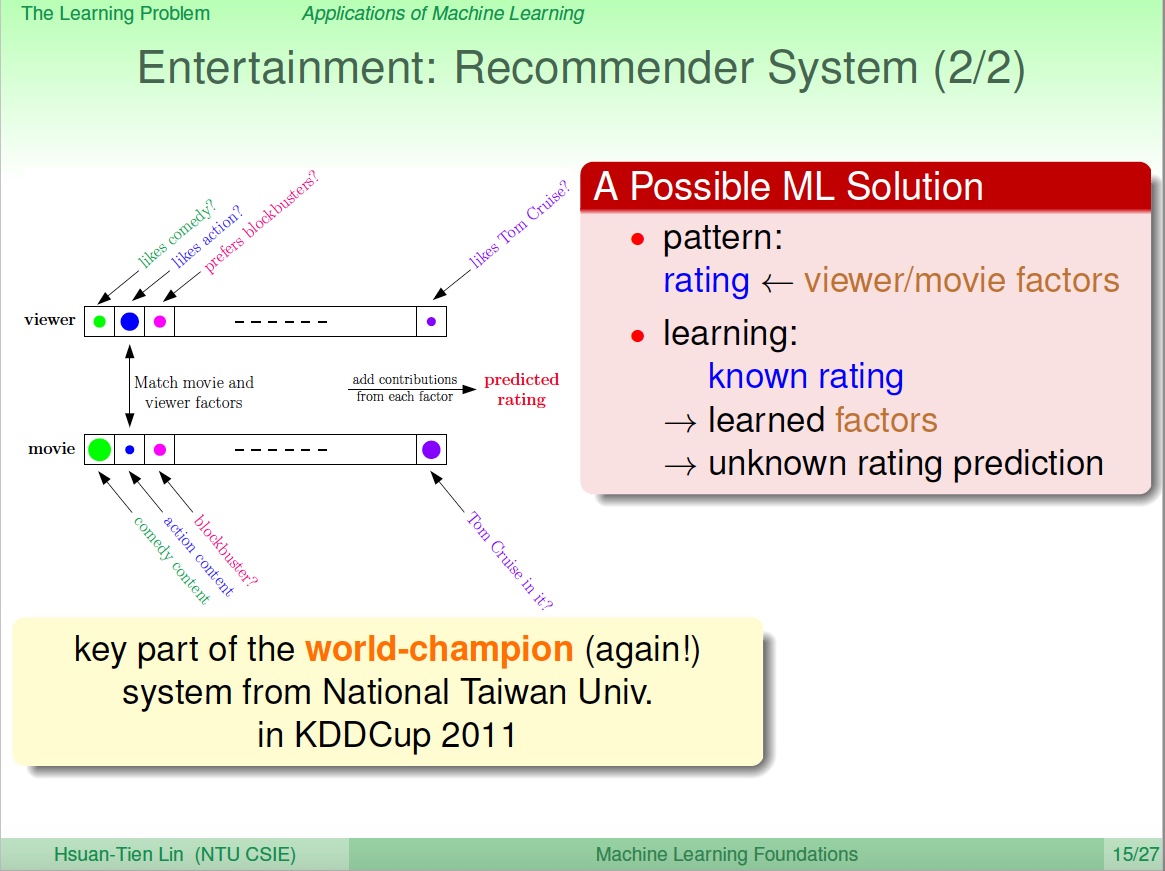
课程分别从衣食住行、教育、娱乐六个角度分别给出了六个不同的机器学习问题样例,我们以娱乐领域中的推荐系统场景为例进行介绍
我们拥有数据对于电影的历史评分数据,需要建立模型预测出用户对于没有评分电影的真实分数。换言之,我们要运用机器学习反腐很好的对用户对电影的偏好进行学习建模。
在推荐问题上有两个世界著名的比赛,一个是2006年的Netflix的电影评分竞赛,另一个是2011年的KDDCup雅虎音乐推荐竞赛

一个可能的方法是构造出用于建模的特征向量,通过历史数据估计特征对应的参数向量然后,用未知评分的电影特征与参数向量做内积得到预测评分
tips: 这里可以参考LR或者FM的模型结构
3.机器学习的基本要素
机器学习的公式定义
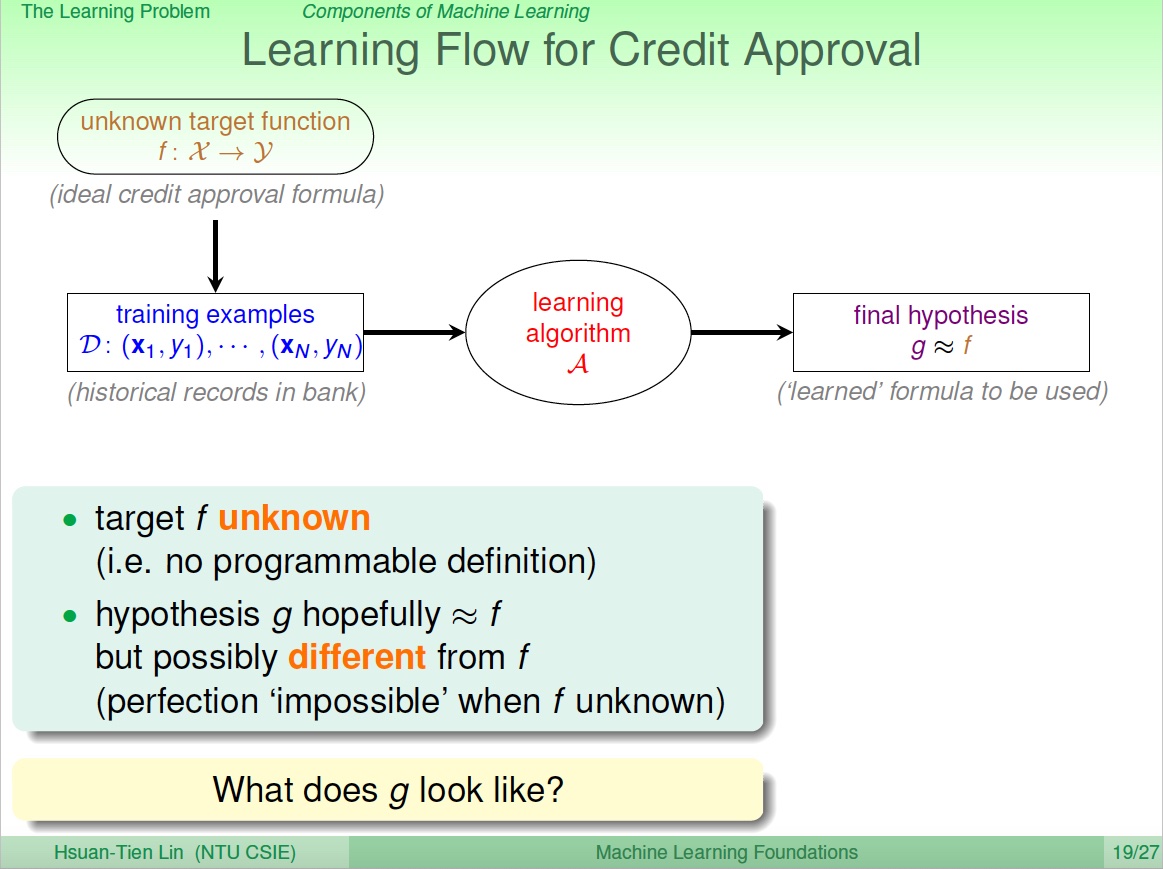
定义一个机器学习问题需要明确几个基本点:
- 问题的输入
- 问题的输出
- 模型要学习的目标函数
- 我们的观测样本(数据)
- 模型的假说(集)

具体而言
- 问题的输入是指模型输入对应的特征集合
- 问题的输出对应我们问题的结果标签(对于分类、回归、排序问题是一致的)
- 模型要学习的目标函数代表未知的潜在规律、模式
- 观测样本是我们的训练数据
- 模型假说是指我们先验地选择的机器学习模型,和对应的学习算法
机器学习的学习过程
"一个机器学习模型根据观测样本通过一定的学习算法学习一个逼近目标函数的模型假说的过程称为机器学习的学习过程"
模型假说存在无数种可能,可以是基于简单规则,可以是传统统计学模型,也可以是神经网络或决策树复杂模型。所有的模型假说可以作为一个集合,我们成为模型假说集
那么机器学习模型就是要在假说集中寻找到一种最为接近目标函数的模型假说,和对应的学习算法。
tips:这里为什么要将模型假说和对应的学习算法分开说明,是因为两者在机器学习模型学习过程中的定位不同。模型假说决定的是假说逼近目标函数的数学结构,学习算法则是在结构确定的情况下通过优化假说的参数逼近目标函数真实的分布情况
4.机器学习和其他领域的区别和联系
机器学习与数据挖掘
机器学习和数据挖掘联系非常紧密,场景相同,方法类似。

机器学习与人工智能
机器学习是实现人工智能的一种方式,一条路径。

机器学习与统计
机器学习借用了很多统计学的工具和方法,但和统计学看问题的视角不同,更专注求解而非数学上的推论
